
Neural networks are often described as black boxes, reflecting the significant challenge of understanding their internal workings and interactions. We propose a different perspective that challenges the prevailing view. Rather than being inscrutable, neural networks exhibit patterns in their raw population activity that mirror regularities in the training data. We refer to this as the Reflection Hypothesis and provide evidence for this phenomenon in both simple recurrent neural networks (RNNs) and complex large language models (LLMs). Building on this insight, we propose to leverage cognitively-inspired methods of chunking to segment high-dimensional neural population dynamics into interpretable units that reflect underlying concepts. We propose three methods to extract these emerging entities, complementing each other based on label availability and neural data dimensionality. Discrete sequence chunking (DSC) creates a dictionary of entities in a lower-dimensional neural space; population averaging (PA) extracts recurring entities that correspond to known labels; and unsupervised chunk discovery (UCD) can be used when labels are absent. We demonstrate the effectiveness of these methods in extracting entities across varying model sizes, ranging from inducing compositionality in RNNs to uncovering recurring neural population states in large language models with diverse architectures, and illustrate their advantage to other interpretability methods. Throughout, we observe a robust correspondence between the extracted entities and concrete or abstract concepts in the sequence. Artificially inducing the extracted entities in neural populations effectively alters the network's generation of associated concepts. Our work points to a new direction for interpretability, one that harnesses both cognitive principles and the structure of naturalistic data to reveal the hidden computations of complex learning systems, gradually transforming them from black boxes into systems we can begin to understand.
Turning “Black Boxes” Into Interpretable Systems: Leveraging the Human Characteristic of Understanding to Interpret Neural Networks
TL;DR. We argue that neural networks aren’t opaque by nature. Their internal population activity reflects regularities in the data. If we segment those dynamics into chunks—interpretable, recurring patterns — we can map them onto concrete or abstract concepts, and steer a model's behavior by activating the right chunk at the right time.
Let's unpack the core pieces of this idea:
Data is compositional
Naturalistic data contains compositional structure at multiple levels.
Humans and animals exhibit behaviors that reflect—and exploit—the compositional structure in the data.
The Reflection Hypothesis
We posit that raw population activity in neural networks mirrors the statistical regularities of the data they learn to predict.
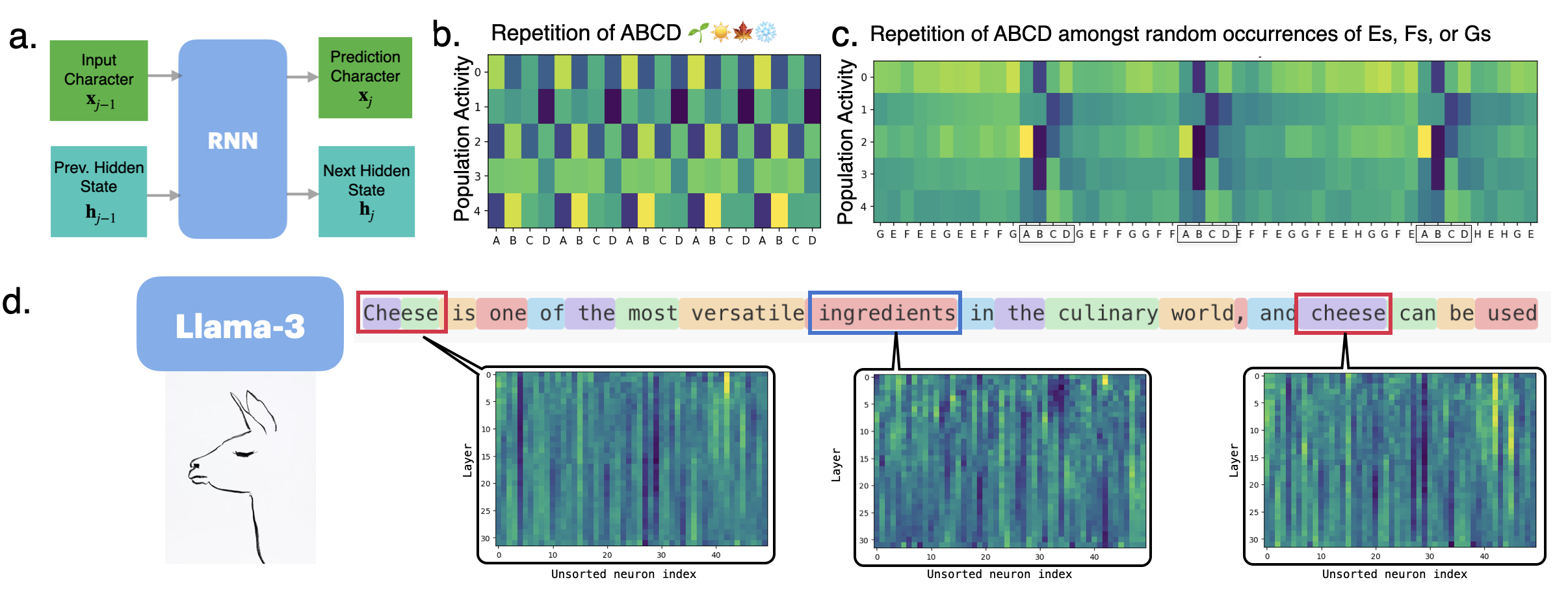
**We check this hypothesis in Simple recurrent networks (RNNs) and Large language models (LLMs).
Across both, we find recurring internal states that align with meaningful concepts—sometimes concrete (e.g., tokens, phrases, entities), sometimes abstract (e.g., grammatical roles, task modes).
From reflections to chunks
Humans handle the complexity of perceptual data by chunking—grouping elements that co-occur into higher-level units (words, phrases, visual entities). We propose applying the same strategy to neural activity: segment high-dimensional population activity into interpretable chunks that act like concepts.
Think of a chunk as:
- a recurring population pattern,
- that predicts what the model will do next,
- and corresponds to a pattern we can identify.
We propose complementary ways to find chunks
1) Discrete Sequence Chunking (DSC)
- Learns a dictionary of recurring patterns in small RNNs.
- Use when you want compact, discrete “atoms” of computation.
- Benefits: fosters compositionality; helps avoid catastrophic forgetting.
2) Population Averaging (PA)
- Finds label-aligned population states and prototypes.
- Use when you have labels and want clean, grounded entities.
- Benefits: simple, fast, and easy to steer; ties directly to human-named concepts.
3) Unsupervised Chunk Discovery (UCD)
- Discovers recurring, stable chunks without labels.
- Use when labels are missing or don’t capture emergent abstractions.
- Benefits: reveals hidden modes and task phases standard supervision misses.
What we see across models
- RNNs: Chunks encourage compositional structure—you can see neural activity patterns that align with input features and behavioral regularities.
- LLMs: We find recurring neural states tied to linguistic or task concepts across diverse architectures. These states act like internal waypoints the model revisits when processing the same concept.
- Interventions: If you induce (activate) a learned chunk at the right moment, the network shifts its generation toward the associated concept—evidence that chunks aren’t just correlations; they’re causally influencing the computation.
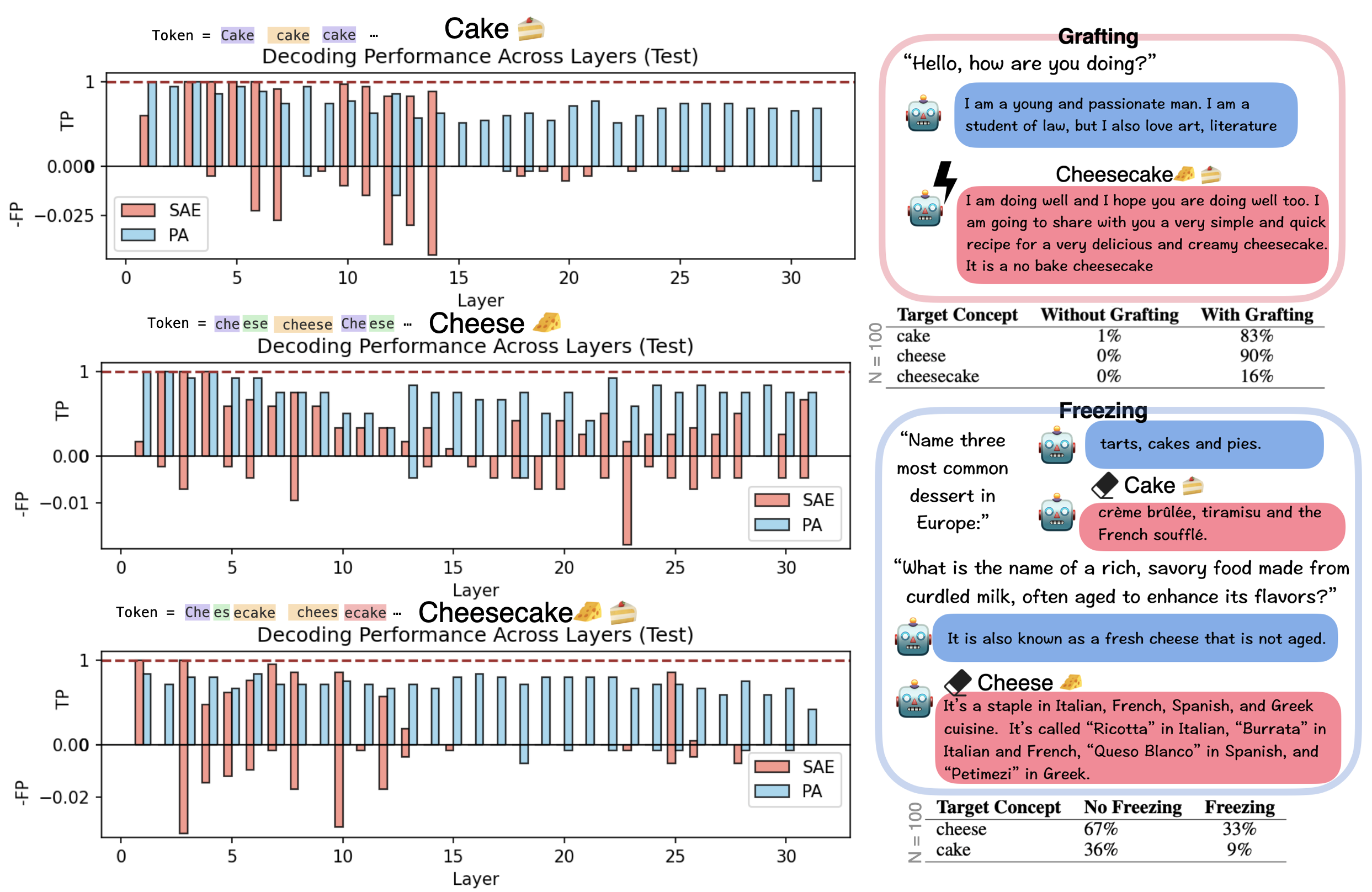
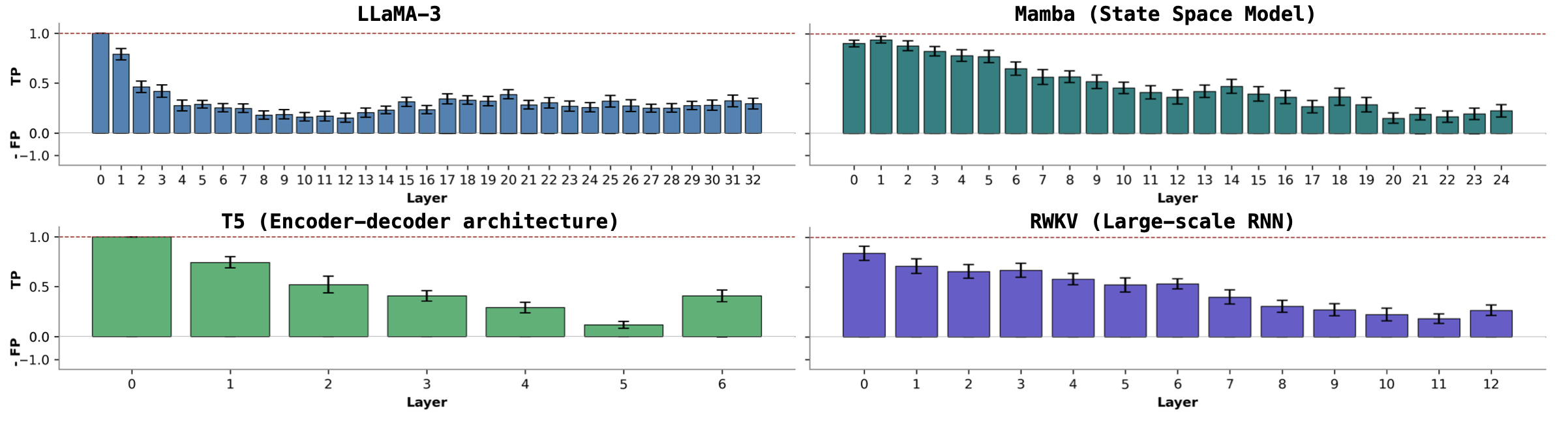
Why this matters
- Interpretability that scales: Work at the level of population dynamics, not single neurons, to reveal how LLMs actually compute.
- Concept-level handles: Chunks give you identifiable, reusable units you can reason about, visualize, and compose.
- Steerability: Causal interventions on chunks open a path to safe, targeted control—steer models by activating desired chunks.
- Bridging cognitive science and ML: Chunking is a human strategy for taming complexity; importing it brings human-legible structure into interpretability.
Why “black box” is the wrong starting point (takeaway)
Neural networks are often labeled black boxes because billions of unit interactions feel inscrutable—but if you inspect population activity (the joint activity of many units over time), structure emerges: recurring patterns that mirror regularities in the training data. Treat this space as concept-like chunks, and you can read out what the model knows, compose those pieces to explain behavior, and even steer computation. In short, don’t assume inscrutability—look for reflections of the data inside the network, and the “black box” starts to look like a system we can understand.
Want to know more?
For many more details, experiment, and analysis, please check out our paper to be published in NeurIPS 2025! It is available at https://arxiv.org/pdf/2505.11576. If you are attending, we are always excited to discuss and answer questions. Our code is available on GitHub as well, at https://github.com/swu32/Chunk-Interpretability.