
Vision-Language Models (VLMs) trained with contrastive loss have achieved significant advancements in various vision and language tasks. However, the global nature of contrastive loss makes VLMs focus predominantly on foreground objects, neglecting other crucial information in the image, which limits their effectiveness in downstream tasks. To address these challenges, we propose COSMOS: CrOSs-MOdality Self-distillation for vision-language pre-training that integrates a novel text-cropping strategy and cross-attention module into a self-supervised learning framework. We create global and local views of images and texts (i.e., multi-modal augmentations), which are essential for self-distillation in VLMs. We further introduce a cross-attention module, enabling COSMOS to learn comprehensive cross-modal representations optimized via a cross-modality self-distillation loss. COSMOS consistently outperforms previous strong baselines on various zero-shot downstream tasks, including retrieval, classification, and semantic segmentation. Additionally, it surpasses CLIP-based models trained on larger datasets in visual perception and contextual understanding tasks.
Introduction
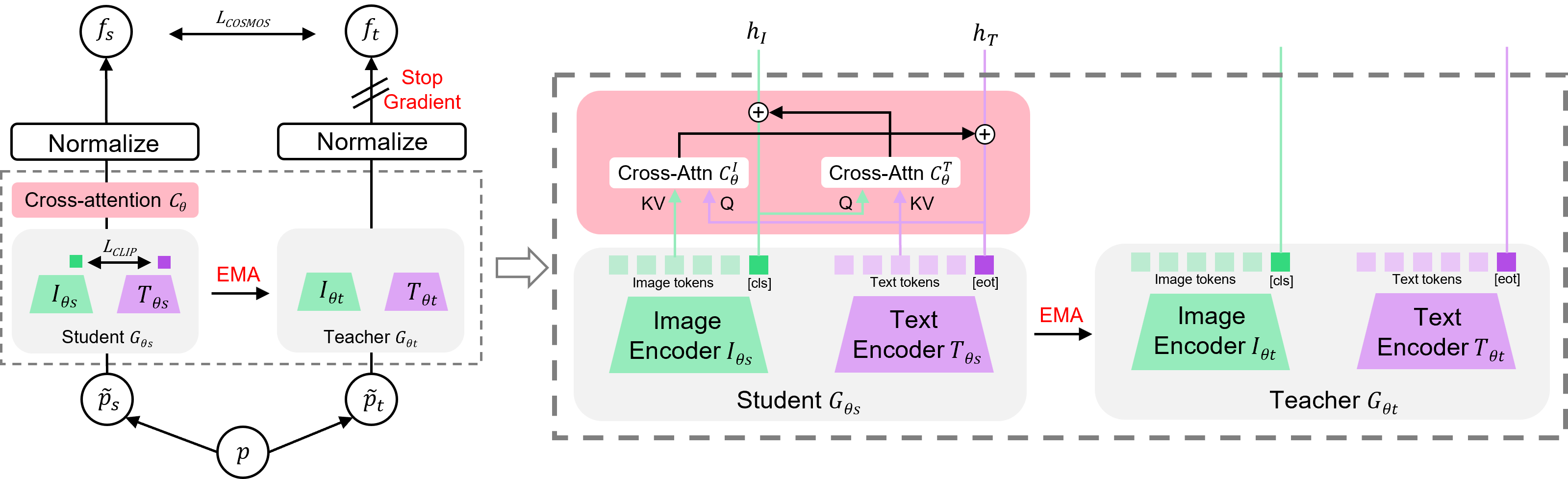
CLIP uses an instance-level contrastive loss to learn text and image representations, where the text gets embedded close to its corresponding image. The contrastive loss function is inherently global, as it matches the entire image to the text. This leads to the dominant objects in the image suppressing the recognition of other smaller objects, which results in poor performance for dense prediction tasks, such as semantic segmentation. In order to overcome this limitation, we propose COSMOS, to learn CrOSs-MOdality embeddings through Self-distillation. Unlike previous self-supervised methods, COSMOS incorporates a unique text-cropping strategy and a cross-attention module to learn multi-modal representations for various downstream tasks.
COSMOS
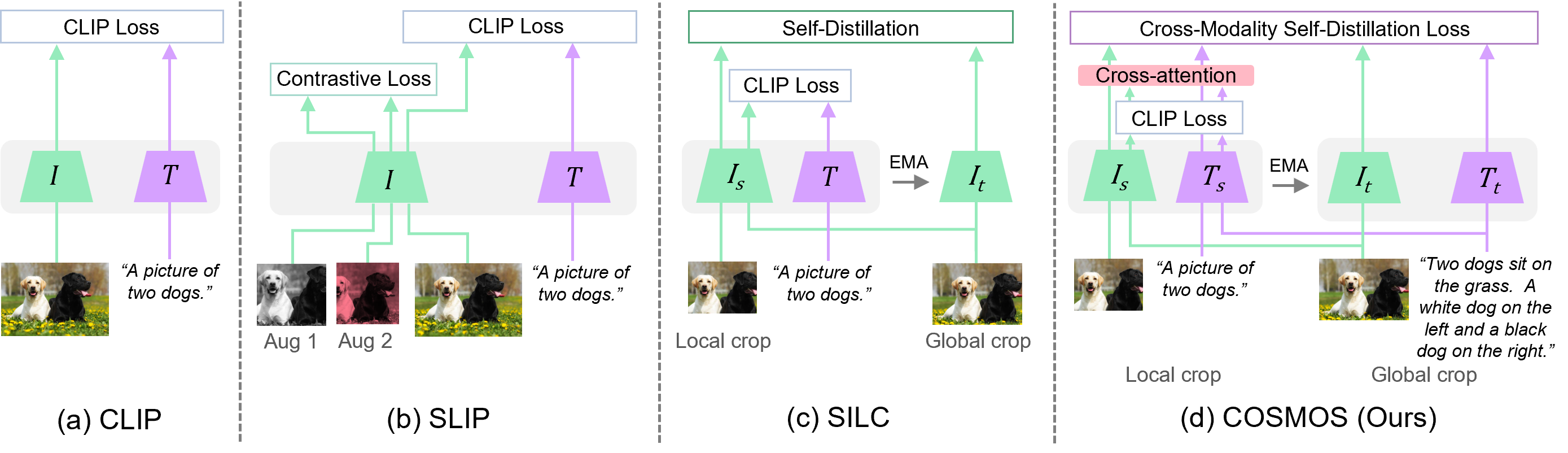
We illustrate our COSMOS framework compared to other methods based on CLIP with self-supervised approaches. and denote the image and text encoders, respectively. (or ) and (or ) represent the teacher and student image (or text) encoders, where the teacher is an Exponential Moving Average (EMA) of the student. (a) CLIP: image and text embeddings are aligned during training. (b) SLIP: contrastive loss is computed on sets of two different augmentations. (c) SILC: self-distillation loss is obtained between local and global crops of the same image. (d) COSMOS: the cross-attention module is utilized to generate cross-modal representations which are optimized through the cross-modality self-distillation loss. We also design global and local crops of image and text pairs for effective self-supervised learning in VLMs.
Image-Text Retrieval
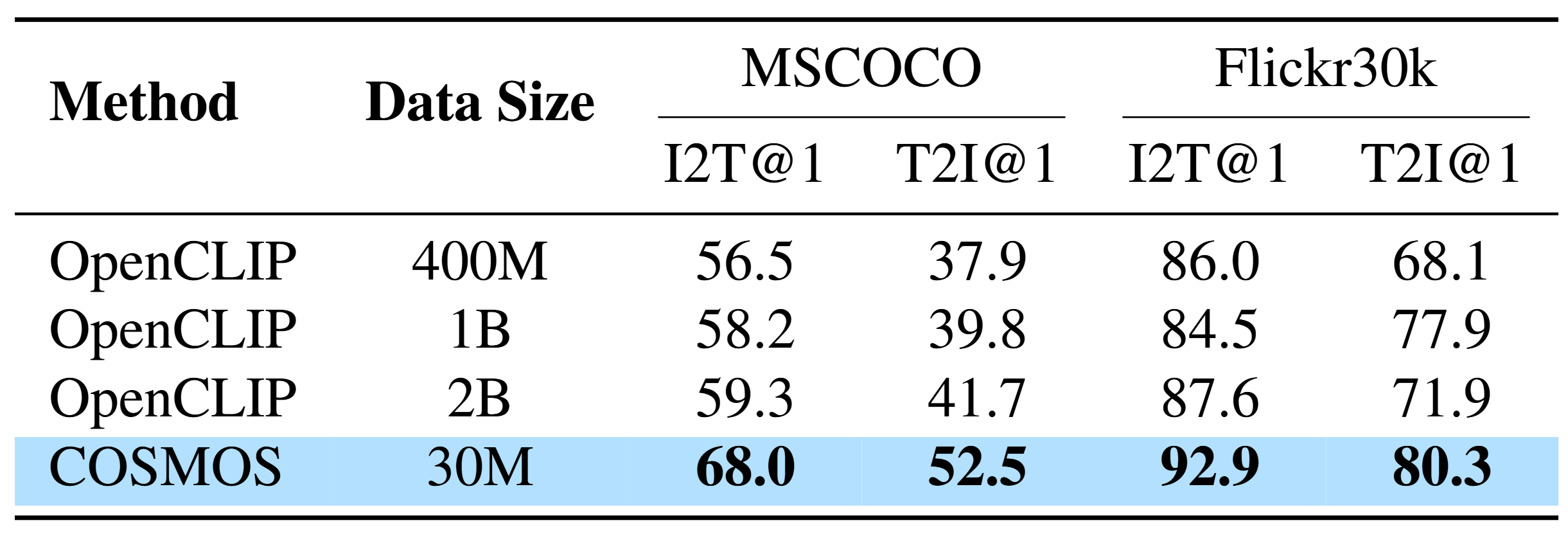
We first present zero-shot image-text retrieval results, measured by R@1, on the Flickr30K and MSCOCO datasets. Using the ViT-B/16 vision encoder architecture, we compare our results with OpenCLIP baselines trained on larger datasets. Remarkably, COSMOS, trained on just 30M samples, significantly outperforms all baselines. This improvement is attributed to the effetive utilization of long caption through cross-modality distillation, enhancing multimodal alignment.
Classification
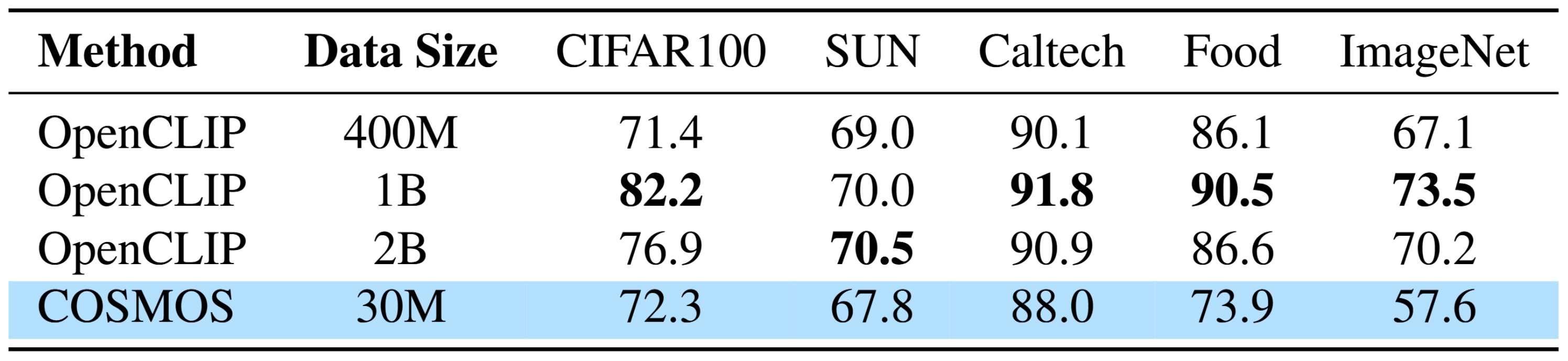
Next, we present zero-shot classification results, measured by top-1 accuracy, on CIFAR-100, SUN397, Caltech101, Food101, and ImageNet. In this experiment, models trained on billions of samples achieve higher accuracy, suggesting that a larger number of images leads to better performance in classification tasks, as the model is required to learn more comprehensive global information.
Semantic Segmentation
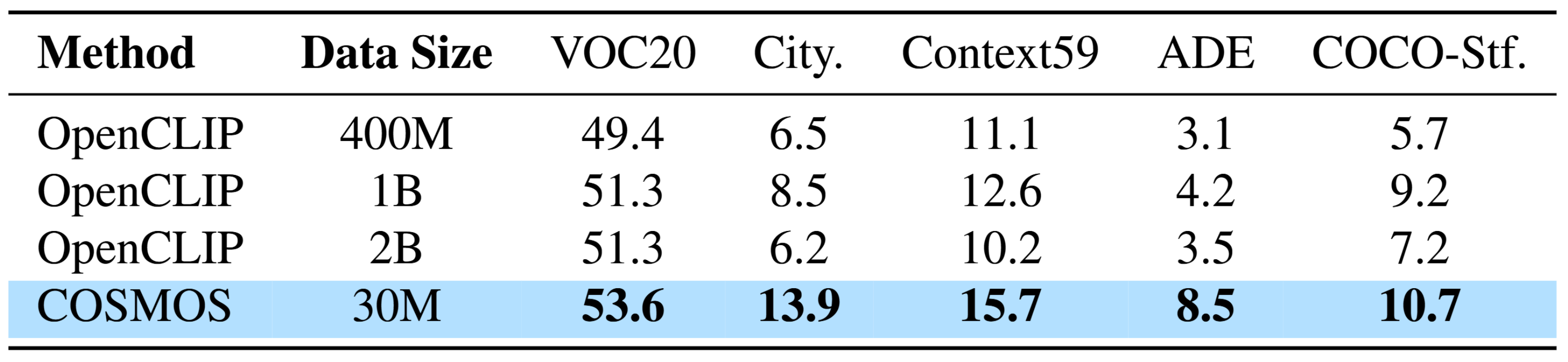
Finally, we demonstrate zero-shot semantic segmentation results, measured by mean Intersection over Union (mIoU), on PASCAL VOC 2012, Cityscapes, PASCAL Context, ADE20k, and COCO-Stuff. COSMOS, trained on only 30M samples, surpasses the best OpenCLIP model trained on 1B samples across all benchmarks. While CLIP-based models often suffer from feature suppression, COSMOS mitigates this issue through cross-modality embeddings and local-to-global matching. These results indicate that COSMOS can effectively generate fine-grained multimodal representations with a much smaller dataset size.
Qualitative Results

We visualize the normalized attention weights of the cross-attention modules for both images and text. For clarity, we use only three colors for the captions, discretized by their original weight values (dark blue for low value, light green for intermediate value, and yellow for high value). Image attention results are based on the input text, while
text attention results are conditioned on the input image. The qualitative results illustrate that various objects are
highlighted in both the image and the text, regardless of their location and size.
Want to know more?
For more details, please check out our paper published in CVPR 2025! It is available at https://arxiv.org/abs/2412.01814. Our code is available on GitHub as well, at https://github.com/ExplainableML/cosmos.