
Concept Bottleneck Models (CBMs) and other interpretable models show great promise for making AI applications more transparent, which is essential in fields like medicine. Despite their success, we demonstrate that CBMs struggle to reliably identify the correct concepts under distribution shifts. To assess the robustness of CBMs to concept variations, we introduce SUB: a fine-grained image and concept benchmark containing 38,400 synthetic images based on the CUB dataset. To create SUB, we select a CUB subset of 33 bird classes and 32 concepts to generate counterfactual images which substitute a specific concept, such as wing color or belly pattern. We introduce a novel Tied Diffusion Guidance (TDG) method to precisely control generated images, where noise sharing for two parallel denoising processes ensures that both the correct bird class and the correct attribute are generated. This novel benchmark enables rigorous evaluation of CBMs and similar interpretable models, contributing to the development of more robust methods.
CBMs Fail to Generalize to Novel Combinations of Known Concepts
Interpretable models, such as Concept Bottleneck Models (CBMs), play a crucial role in deploying deep learning systems across many real-world applications. However, our findings reveal that when these models encounter novel combinations of familiar concepts (such as a Blue Jay with a yellow crown) they frequently fail to accurately predict the modified concept. This limitation raises concerns about their reliability as tools for interpretability. To assess this capability, we curated a novel synthetic dataset comprising 38,400 images: Substitutions on Caltech-UCSD Birds-200-2011 (SUB).
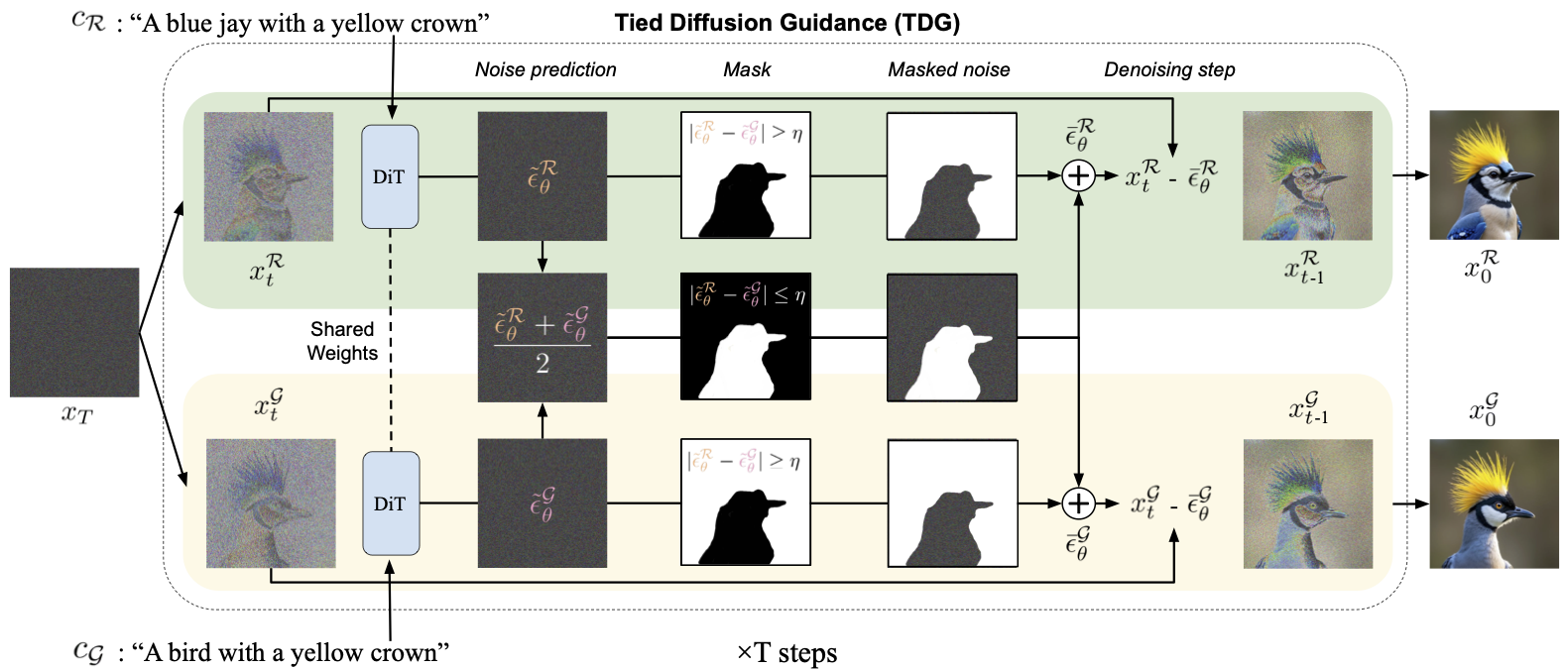
Tied Diffusion Guidance (TDG)
To generate the SUB dataset, we introduce a test-time modification designed to produce fine-grained attribute changes within known classes, which we call Tied Diffusion Guidance (TDG). TDG aims to generate an image of a reference class , incorporating a target attribute substitution , while removing the original attribute . To support this controlled generation, we introduce a guidance class , where more naturally occurs.
We generate two prompts corresponding to and , producing class-conditional predictions and in parallel. These predictions are then tied by partially aligning them: the th percentile of the most similar elements between the two predictions are replaced with their average, while the remaining, more dissimilar elements are left unchanged. This ensures that the generations are identical in an fraction of regions, only being allowed to deviate in key, often caption-required locations. The value of follows a scheduled progression: it begins with a warm-up phase (full sharing, ), transitions through an exponential decay phase (gradually reducing ), and ends with a cool-down phase (no sharing, ), allowing the model to freely generate distinguishing features.
SUB Benchmark
We introduce SUB, a benchmark with fine-grained attribute edits to evaluate concept prediction faithfulness. SUB builds upon CUB's [^2] classes and attributes, comprising synthesized images of bird classes with single substituted attributes generated via TDG with FLUX [^1]. It includes unique combinations of CUB species and target attributes , with 50 images per combination. A vigorous filtering process removes classes, attributes, pairings, and samples which are inaccurate to generate or automatically detect. Human validation on SUB ensures that individual target attributes were successfully generated with accuracy of or greater.
Evaluation

Qualitatively, we see that TDG helps support fine-grained attribute modification where FLUX [^1] fails out-of-the-box (prompting). We can further understand TDG with the guidance image , but only the reference image is included in SUB.
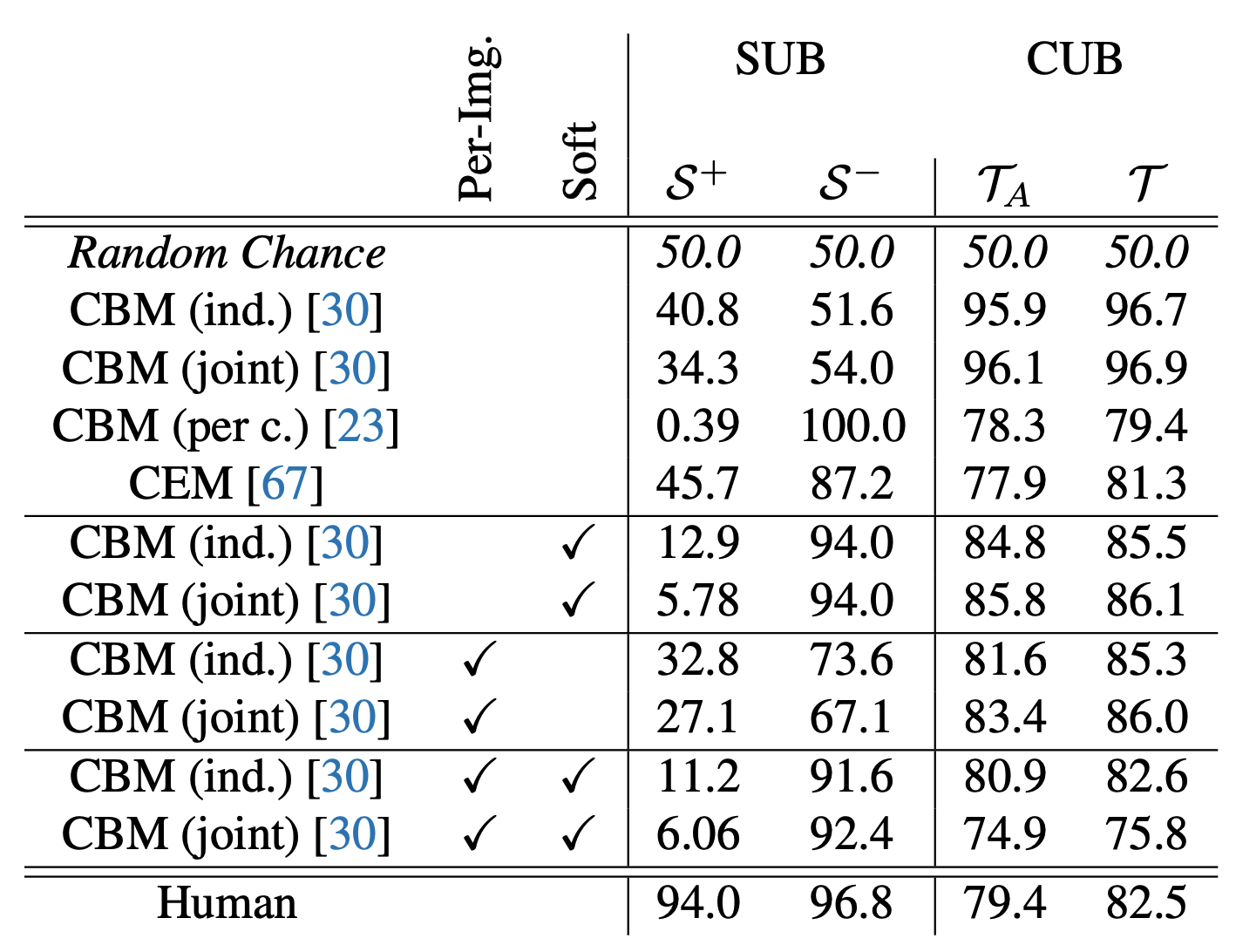
When evaluating existing CBMs on the SUB dataset, we assess each model's ability to (1) detect the target attribute and (2) correctly identify the removal of the original attribute . For comparison, we also measure standard concept prediction accuracy on the original CUB dataset (), as well as on the subset of CUB attributes used in SUB ().
Despite achieving high accuracy on both and , all CBMs perform poorly on SUB, failing to generalize to novel combinations of familiar concepts. This highlights a key limitation: their predictions are not robustly grounded in the underlying target concepts.
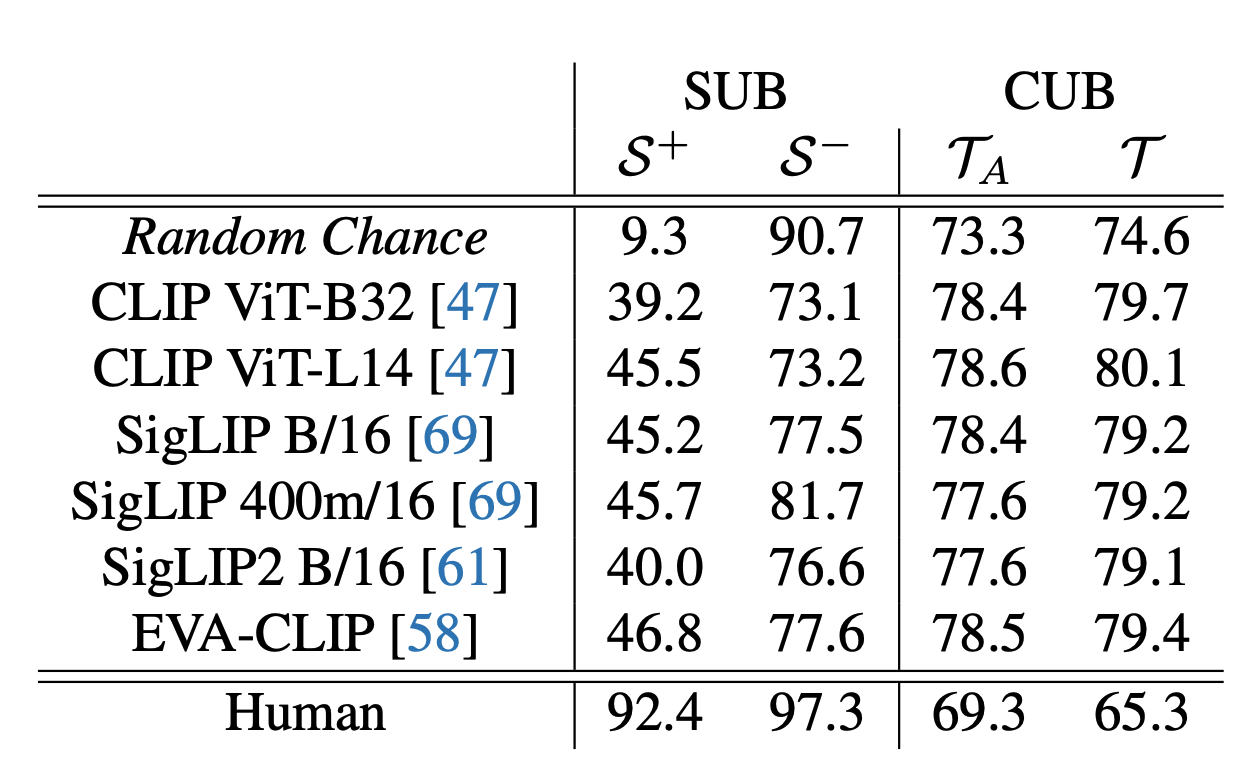
Since many interpretable models rely on VLM backbones to generalize to open-vocabulary settings without explicit supervision, we also evaluate several commonly used VLMs. To enable classification with these models, we define an attribute group (e.g., all possible crown colors) and treat the attribute with the highest cosine similarity to the image as true, labeling all other attributes within the group as false.
We find that while prediction accuracy for is above random chance across the evaluated VLMs, overall performance remains low, with accuracy still falling below . Furthermore, predictions are consistently below chance, indicating a specific type of hallucination: the models incorrectly identify the original attribute as present, even when it has been explicitly removed. These results suggest that, despite advances in large-scale pretraining, generalizing to novel attribute configurations remains a significant challenge for VLMs.
Want to know more?
For many more details, background, and analysis, please check out our paper to be published in ICCV 2025! It is available at https://arxiv.org/pdf/2507.23784. If you are attending, we are always excited to discuss and answer questions. SUB is available on HuggingFace at https://huggingface.co/datasets/Jessica-bader/SUB, and our code is available on GitHub as well, at https://github.com/ExplainableML/sub.
References
[^1]: Black Forest Labs. FLUX. 2024. https://github.com/black-forest-labs/flux
[^2]: Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The caltech-ucsd birds-200-2011 dataset. In California Institute of Technology Technical Report, 2011